State of the Graph is continuing its world tour with one of the most visible parts of the ecosystem: Graph Databases.
Graph databases are where graph theory becomes a living system: a place to store, query, and analyze entities and their relationships at scale. They power use cases such as real‑time recommendations, fraud and risk detection, network operations, and AI‑driven applications across many industries.
This category is anything but uniform: property‑graph engines, RDF triple stores, and an expanding set of multi‑model platforms all make different trade‑offs around data models, workloads, deployment, and tooling.
This first version of the Graph Databases catalog is an attempt to present that landscape in a single, structured, vendor‑inclusive view. We aim to enable users to see how engines compare across graph models, storage architectures, transaction guarantees, scale‑out strategies, query languages, and the surrounding ecosystem.
The catalog is split into two tables: a main table for current, primary graph databases, and a second table for legacy, deprecated, long‑tail, and graph‑adjacent products that provide useful context but aren’t in the main list.
Graph Database Market Size
According to Fortune Business Insights, the global graph database market size is projected to grow from $2.85 billion in 2025 to $15.32 billion by 2032, exhibiting a CAGR of 27.1%. This kind of growth reinforces why it’s worth having a clear, vendor‑inclusive view of the landscape rather than relying on ad‑hoc snapshots.
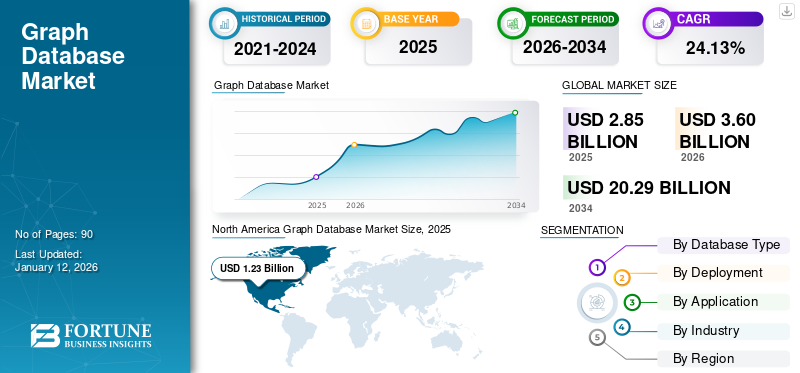
Source: https://www.fortunebusinessinsights.com/graph-database-market-105916
What We Included in Graph Databases
This first release focuses on a coherent slice of the space that practitioners can act on. The catalog is limited to offerings that provide a graph model as a first‑class capability, not just a thin feature bolted onto a non‑graph store.
Entries span property‑graph databases, RDF triple stores, multi‑model systems with promoted graph support, plus a curated set of legacy, deprecated, long‑tail, or graph‑adjacent products in a second, extended table.
Each entry in the catalog captures how a product treats graph models, storage, scale‑out, workloads, query languages, and deployment options, along with a few notes on status and positioning.
Inclusion Criteria: What This Catalog Is (and Is Not)
To maintain coherence, we applied three inclusion criteria across commercial and open‑source offerings. An offering belongs in the Graph Databases catalog only if it satisfies all three:
1. First‑class Graph Model
The database must expose a clear property graph or RDF model, with nodes (vertices) and edges (relationships) as core structures, and support full create, read, update, and delete (CRUD) operations on those graph elements via a graph‑aware API or query language, rather than just emulating graph patterns through joins or custom code.
- LPG (Labeled Property Graph) systems represent entities and relationships with labels and properties on both nodes and edges.
- RDF (Resource Description Framework) triple stores model data as triples (subject, predicate, object), often with richer semantic layers.
- Multi‑model platforms are included when they provide explicit graph abstractions alongside other models, not merely a “relationship table” pattern.
Engines that only support graph‑like queries over non‑graph storage, without a graph model that supports CRUD, are out of scope.
2. First‑Class Graph Querying
There must be a first‑class, graph‑aware query language or API, such as Cypher, Gremlin, SPARQL, GQL, or an equivalent interface. Concretely, this means:
- Traversals, pattern matching, and path queries are expressed in a dedicated graph syntax or API.
- Users can call built‑in graph operations without re‑implementing traversal logic from scratch.
Products that require you to hand‑craft graph logic purely with generic SQL, map‑reduce jobs, or stored procedures, with no graph‑specific language or API, do not qualify for this catalog.
3. Deployable Product
The offering must have a clear deployment story suitable for real‑world use, not just experiments:
- Distribution as open source or commercial software.
- Deployment as SaaS, managed in the customer’s cloud, or self‑managed on‑prem or in customer cloud environments.
- A reasonable path to running in production, including versioned releases and basic operational guidance.
Experimental research prototypes, unmaintained side projects, or research papers without a deployable implementation are outside the current scope.
What the First Version Tells Us
Even in this first iteration, several patterns stand out across the graph database landscape.
Property Graph, RDF, and Multi‑Model Coexist
No single graph model has “won.” Instead, we see three major families:
- LPG systems thrive on operational and mixed workloads, emphasizing flexible schemas, expressive pattern matching, and transactional updates.
- RDF triple stores cluster around standards‑driven knowledge‑graph scenarios, with strong support for URIs, SPARQL, ontology, inference, and semantic interoperability.
- Multi‑model platforms combine graphs with other representations, so teams can keep heterogeneous data in a single engine and choose the right model for each use case.
The catalog surfaces these differences directly in the graph‑model field, and the notes highlight when the graph is central versus “graph‑adjacent”.
Distributed, Disk‑Based Engines are the Norm
Most current products position themselves as distributed, disk‑backed systems with clustering and sharding, capable of scaling out across multiple nodes or availability zones.
- Flagship engines and cloud services emphasize horizontal scalability, High Availability (HA), and resilience.
- In‑memory or memory‑first systems target real‑time or high‑performance workloads on more constrained but very fast working sets.
- Single‑node offerings remain relevant for embedded scenarios, smaller deployments, and specialized analytics, explicitly marked as “single‑node only” in the catalog.
This makes it easier to answer questions like: “What can we use if we need global scale and multi‑region failover?” versus “What fits an embedded analytics use case on a single machine?”
OLTP and Analytics Often Blend
The workload-focused field shows that many engines have moved beyond a strict transactional vs analytical divide.
- Several products explicitly support both OLTP and Analytics/OLAP workloads, and are marketed as suitable for hybrid transactional‑analytical processing on graphs.
- A subset emphasizes analytics‑first positioning, targeting heavy read‑intensive graph queries and long‑running traversals over large graphs.
- Others lean into operational use cases such as fraud checks in the transaction path or personalization at request time, while still exposing analytical capabilities for more complex graph exploration.
Hybrid graph workloads are increasingly table stakes rather than an edge case.
Query Languages Form Clear Clusters
The query‑language landscape resolves into a few recognizable clusters:
- Cypher/openCypher across many LPG engines, with some early adopters offering support for the newly minted ISO standard, GQL.
- Gremlin (Apache TinkerPop) as a traversal‑based lingua franca for certain ecosystems and cloud services.
- SPARQL 1.1 anchoring RDF triple stores and semantic platforms.
- SQL and proprietary graph languages used either alongside graph‑specific languages or as the primary access path in multi‑model products.
For teams, this makes it easier to reason about skill reuse: “If my engineers already know Cypher or SPARQL, which engines will feel familiar?”
Ecosystems and Deployment Options Matter
Tooling and deployment dimensions highlight how much the surrounding ecosystem influences adoption:
- Admin UIs and query workbenches are now common expectations, not nice‑to‑haves.
- Drivers for major languages (Java, Python, JavaScript, and beyond) and connectors to Spark, Kafka, BI tools, or GIS stacks are central to how these databases integrate into real systems.
- Deployment patterns span fully open‑source, self‑managed engines; commercially supported distributions; and SaaS or managed‑service offerings tied to major cloud providers
These dimensions help practitioners filter by constraints they actually live with: “We must self‑host,” “We prefer a managed service,” or “We want open source as a starting point.”
How Graph Databases Fit into State of the Graph
Graph Databases are one chapter in a larger State of the Graph project that’s trying to make sense of how different pieces of the ecosystem fit together. This installment stays close to the data layer: engines that store relationships, serve queries, and set the boundaries for what you can realistically do with graph workloads.
Other parts of the stack, such as Graph Analytics, Graph Engines, Graph Visualization, Knowledge‑Graphs, GraphAI, and Graph Application Development, will each get their own treatment.
Rather than repeating the same template everywhere, we’re tuning definitions and criteria by category so that each catalog reflects how that slice of the community actually works, while still aligning with a coherent overall map.
Help Us Improve This First Cut
This is a first pass, not a definitive handbook. The boundaries between “database,” “engine,” and “graph‑adjacent system” are messy in practice, and we’ve had to make judgment calls, especially for legacy, deprecated, long‑tail, and graph‑adjacent products. There may be omissions, rough edges, or places where the notes could be sharper.
If you work with graph databases (whether you ship them, run them in production, or evaluate them for your team), we’d value your input. In particular:
- What did we leave out that you rely on?
- Where does the catalog misrepresent a product’s model, workload focus, or deployment story?
- Are there hybrid systems we should treat differently because graph is “one of many” rather than the center of gravity?
- Which extra dimensions would actually help you compare options (for example, security posture, observability, operation at multi‑region scale, or licensing constraints)?
Spend a few minutes with the Graph Databases catalog and let us know what’s wrong, missing, or under‑explained. The goal is to iterate quickly, fold community feedback back into the data, and have each new version do a better job of reflecting how graph technology is used in the real world.
Leave a Reply