State of the Graph is mapping a new frontier: how graphs are being used inside AI systems.
GraphAI is the category where graph structure stops being passive infrastructure and starts doing active work, shaping what models retrieve, what agents remember, and what machine learning algorithms learn.
That shift is the unifying logic of this catalog.
In GraphRAG, the graph sits in the retrieval path, selecting and grounding the context sent to a large language model. In Graph Memory, the graph organizes what agents know and have done, making long-term behavior inspectable and structured. In Graph Neural Networks (GNNs), the graph is the native input to machine learning itself, encoding relationships as a first-class signal for prediction and inference.
Three different moments in an AI pipeline, one consistent principle: the graph is part of how the AI thinks, not just where the data lives.
The global GNN market size was valued at $1.45 billion in 2024, and is forecasted to hit $13.2 billion by 2033, growing at a CAGR of 28.4% as per Market Intelo.
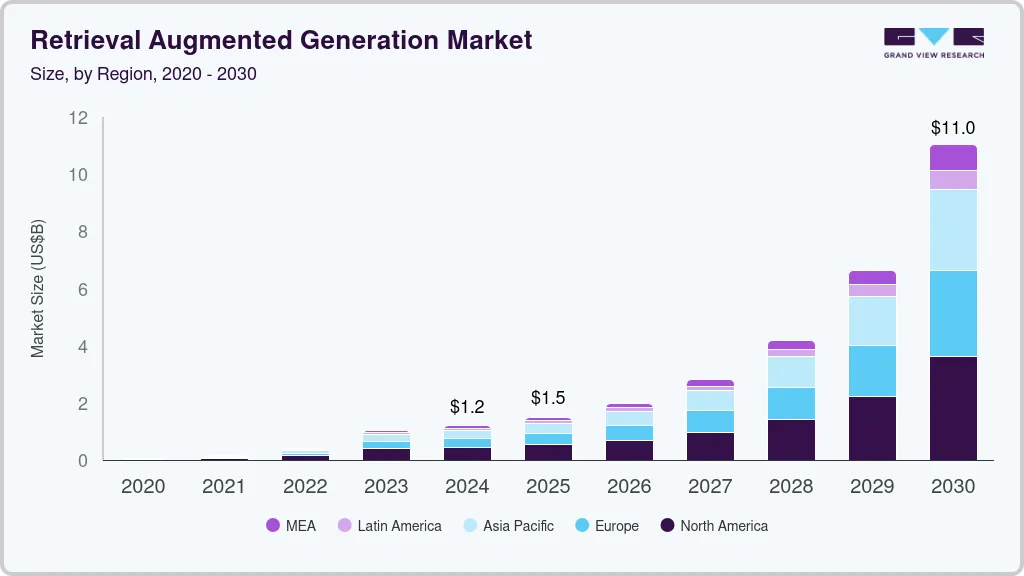
The overall RAG (Retrieval Augmented Generation) market size was estimated at $1.2 billion in 2024 and is projected to reach $11.0 Billion by 2030, growing at a CAGR of 49.1% as per Gran View Research. GraphRAG represents a specialized, high-growth area focusing on complex, interconnected data.
What We Included in GraphAI
GraphAI builds on an established foundation. Graph neural networks (GNNs) represent the original graph learning discipline, where graphs serve as native training input for machine learning models.
What has changed is that graphs are now appearing throughout AI pipelines, not just at training time. GraphRAG and Graph Memory are the expanding frontier: graphs shaping inference, retrieval, and agent cognition in real time.
The catalog tracks offerings where graph-based AI is the main event, not a peripheral feature. We organize them into three GraphAI types that reflect distinct, but increasingly overlapping design patterns.
GraphRAG
This type includes products that put a graph directly in the retrieval path for large language models. These are engines, databases, and retrieval layers you can deploy to give LLMs better context and grounding.
To qualify, an offering must use a graph structure, such as a knowledge graph or other graph store, to select and shape the context sent to the LLM. It must also ship concrete, reusable capabilities for this job: documented GraphRAG features, APIs, SDKs, templates, or patterns that teams can pick up and use across multiple domains.
Graph Memory
Here we examine systems where graph structure is the architecture of memory, not just a data format sitting behind it. Entries in this type treat agents or agentic workflows as a primary target and provide long-term or shared memory that is explicitly structured as a graph, or as a hybrid of graph and vector representations.
They also expose some form of trace or reasoning representation: decision graphs, graph-based histories, or visual flows of reasoning steps that make agent behavior inspectable over time. The emphasis is on platforms where graph-structured memory is a first-class design choice, not an afterthought bolted onto an orchestration layer.
GNNs (Graph Neural Networks)
The GNN type focuses on learning on graphs. It includes graph neural network libraries and platforms that provide GNN layers and models as first-class citizens, along with the practical machinery to train and run them on real graph data.
To make the cut, a project or product needs more than a research prototype: it must expose usable APIs or pipelines, and demonstrate meaningful adoption, either as a widely used open-source library in the graph ML community, or as an enterprise-positioned graph ML platform with documented deployments.
Across all three types, each row in the catalog captures how a given offering fits into GraphAI, how it connects to your data, what AI and ML capabilities it exposes, and how far it takes you toward production-ready systems.
How We Describe GraphAI Offerings
To make different offerings comparable, the catalog uses a shared set of fields aligned with the real design decisions practitioners face.
Core identity and access: Product name, vendor, description, availability, GraphAI type, query languages and interfaces, and data connectivity. This gives you a quick read on what the product is, who operates it, how you can deploy it, and how developers interact with it.
GraphRAG capabilities: LLM providers and deployment models supported, GraphRAG feature set, embedding and vector search handling, retrieval patterns available, and how the product approaches grounding, explainability, and GenAI maturity.
Graph Memory capabilities: Whether agent workflows are built in or integrated externally, how memory is modeled and stored, whether graph-based views of decisions and traces are available, and what tooling exists for planning, tool orchestration, and inspecting agent behavior over time.
GNN and graph ML capabilities: How graphs are constructed and mapped into training format, what message passing and layer architectures are supported, how features and embeddings are managed, what scaling options exist, how predictive tasks are expressed, and what support exists for experiment management, deployment, and monitoring.
Cross-cutting properties: Explainability, security, access control, governance, and compliance notes. References to primary and secondary sources make clear where each data point came from.
A note on inclusion: because these three types represent structurally distinct design patterns rather than variations on a single theme, each carries its own inclusion tests. An offering is placed in a type only if it satisfies all criteria for that type, not GraphAI criteria in general.
This is a deliberate choice, and a departure from how we have structured inclusion in other State of the Graph categories. It reflects the fact that GraphRAG, Graph Memory, and GNNs involve meaningfully different architectural decisions, not just different feature sets.
Inclusion Criteria: How We Decide Who Belongs
The catalog entries went through a structured review process based on primary documentation, vendor materials, and community usage to decide what belongs.
GraphRAG
Offerings must:
- Use a graph, such as a knowledge graph or graph database, directly in the retrieval or grounding path for large language models.
- Ship explicit, productized GraphRAG or graph‑augmented retrieval capabilities, for example APIs, SDKs, templates, or documented patterns that are part of the product.
- Be reusable as a general GraphRAG or graph‑GenAI capability across multiple domains or use cases, rather than being tied to a single narrow application.
Graph Memory
Offerings must:
- Treat agents or agentic workflows as a primary use case, for example by providing a framework, platform, or memory layer explicitly built for agents.
- Provide long‑term or shared memory that is explicitly structured as a graph or as a hybrid graph‑and‑vector representation, for example a knowledge graph or graph‑indexed memory.
- Expose graph‑based traces, histories, or reasoning and flow views that make agent behavior inspectable over time, as a first‑class part of the system rather than an afterthought.
GNNs (Graph Neural Networks)
Offerings must:
- Provide graph neural networks as a first‑class capability, such as GNN models, layers, or a GNN‑specific framework.
- Support training and/or inference of graph neural networks on real graph data through concrete mechanisms such as APIs, data loaders, pipelines, or managed services.
- Demonstrate meaningful adoption or positioning, either as a widely used open‑source project in the graph ML community or as an explicitly enterprise‑oriented graph‑ML platform.
These boundaries are meant to be firm enough that not every product with “graph” and “AI” in its marketing ends up here, while still flexible enough to include important open-source projects and emerging offerings that clearly center graphs in their AI story.
What This First Version Tells Us
Looking across the entries in this first cut of the GraphAI catalog, a few themes emerge.
GraphRAG is crystallizing. A growing number of graph databases and knowledge graph platforms now include specific GraphRAG features, examples, or SDKs. The question is increasingly not whether you can do GraphRAG, but how well you handle retrieval quality, graph and vector signal integration, and managed tooling.
Graph Memory is diverging. Some agent-oriented offerings focus on orchestration and tool use while leaving memory structure as an exercise for the user. Others make graph-structured memory and explicit traces central to the design. The catalog makes it easier to see who is taking the latter route, which matters if you care about long-term behavior, debugging, and governance.
GNN stacks are maturing. Large open-source libraries and cloud-based frameworks are converging toward more complete workflows, from graph ingestion to distributed training and model deployment. At the same time, a gap remains between research-ready libraries and end-to-end platforms that non-specialists can operate.
Overlaps are becoming the norm. Several vendors appear in more than one GraphAI type. A single platform may provide a graph database with GraphRAG patterns, a graph-structured agent memory layer, and a managed GNN service. The catalog is designed to make those multi-role platforms visible, which matters if you want a cohesive graph-centered AI stack rather than a collection of unrelated components.
How Does GraphAI Relate to the Rest of State of the Graph?
GraphAI sits alongside the other categories in State of the Graph, which cover graph databases, knowledge graphs, graph analytics, graph visualization, and graph application development. Each category looks at a different layer of the stack. The GraphAI catalog focuses specifically on how graphs intersect with generative models, agent memory, and graph-based machine learning, the moments where graph structure becomes part of how AI reasons, rather than simply where data is stored.
FAQ: GraphAI vs. Knowledge Graphs
Why do some vendors show up in both the GraphAI and Knowledge Graph catalogs?
Because they address different layers. An offering can qualify as a knowledge graph platform by providing a first-class graph model, tools to build and query that graph, and a productized knowledge graph capability. The same offering may also provide GraphRAG features, Graph Memory capabilities, or GNN services that satisfy GraphAI criteria. In that case it belongs in both catalogs, but for distinct reasons.
What is the difference between the GenAI section in the Knowledge Graph catalog and the GraphRAG type in the GraphAI catalog?
In the Knowledge Graph catalog, the GenAI section describes how a knowledge graph platform exposes AI capabilities within its knowledge graph: GraphRAG patterns, embeddings, vector search, and LLM integrations that operate on that KG.
In the GraphAI catalog, the GraphRAG type refers to offerings whose core purpose is graph‑powered retrieval for LLMs and memory layers whose primary job is putting a graph in the retrieval path, regardless of what graph backend they sit on.
Can a platform be in one catalog but not the other?
Yes, in both directions. A knowledge graph platform with strong modeling and governance but minimal AI features may appear only in the Knowledge Graph catalog. A GraphAI platform focused on GraphRAG, Graph Memory, or GNNs on top of other backends, without exposing a general-purpose knowledge graph layer, may appear only in the GraphAI catalog.
How should practitioners use both catalogs together?
The Knowledge Graph catalog helps you choose how to model and govern your domain as a graph. The GraphAI catalog helps you choose how to use graphs inside AI systems. Together they give a fuller picture of where graphs fit in your data and AI architecture, and how different vendors cover different parts of that story.
If you are building with GraphRAG, designing agents that rely on structured memory, or deploying graph neural networks, this catalog is a starting point, not the final word. Explore the entries, see where current offerings land, and tell us where the map needs to change. Your feedback will shape the next version and help clarify how graph and AI technologies are coming together in practice.

Leave a Reply