State of the Graph is continuing its tour of the ecosystem with a first deep dive into the Knowledge Graphs category. Knowledge graphs organize information as a network of entities and relationships, often with semantic meaning, so systems can work with connected context rather than isolated records.
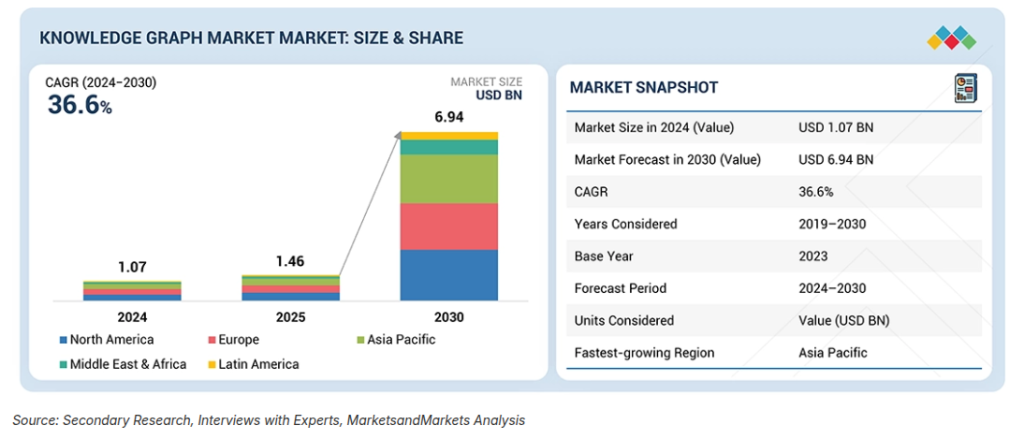
The Knowledge Graph market is estimated to be worth USD 1.07 billion in 2024 and is projected to reach USD 6.94 billion by 2030 at a Compound Annual Growth Rate (CAGR) of 36.6% during the same period, according to MarketsandMarkets.
We view the knowledge graph product category as offering capabilities that go beyond simply storing and retrieving graphs. For each knowledge graph offering, the State of the Graph catalog captures:
- How it models knowledge (property‑graph‑centric, RDF/OWL‑centric, or converged property+RDF).
- Which graph and query languages it supports (for example, Cypher, Gremlin, SPARQL, GraphQL, proprietary graph queries).
- How you construct, integrate, and update the KG (ingestion, automated KG construction, real‑time querying, multi‑hop reasoning).
- Which semantic and metadata capabilities are available (metadata management, ontologies, inferencing, semantic data fabric, lineage, harmonization).
- How users explore and curate the graph (visualization, KG exploration, low‑code tools, collaboration, curation workflows).
- How it supports GenAI (for example, GraphRAG, embeddings, vector search, and agentic AI integration), and how tightly those AI features are coupled to the KG.
- Which trust and explainability features it provides (provenance, lineage, schema governance, audit trails, fact grounding, hallucination mitigation, compliance, uncertainty).
Those capabilities can be offered on top of property graph databases, RDF triple stores, or converged engines (supporting both property graphs and RDF). They may also be offered over virtualized engines, hypergraphs, or other storage systems.
To be included in our catalog, offerings must represent a unified graph of a domain and be presented as something users can actually build and run. Increasingly, that unified graph is the grounding substrate for GenAI: powering GraphRAG, agentic workflows, retrieval with provenance, and safer, more explainable AI behavior.
The knowledge graph catalog brings together dedicated KG platforms, infrastructure providers, and knowledge‑centric search and management tools into a single, structured picture, so you can see who is doing what, where they overlap, and where they differ.
What We Included in Knowledge Graphs
This catalog focuses on offerings in which the knowledge graph layer is central to the product story, not just a checkbox or a marketing tagline. You will see three broad types of entries:
- Dedicated knowledge graph platforms such as AllegroGraph, GraphDB, eccenca, Stardog, TopQuadrant, and TrustGraph, which revolve around KGs, semantics, governance, and trust.
- Platform/infrastructure providers such as Neo4j, Memgraph, FalkorDB, ArangoDB, and Oracle Graph are general‑purpose graph or data platforms that ship clear “enterprise knowledge graph” or GraphRAG patterns.
- Knowledge management/search layers such as metaphactory, Prometheux, and Ontopic Studio that surface KG‑backed search, exploration, and curation for business and technical users.
Mapping knowledge graph product capabilities on graph data modeling, querying, ingestion and integration, as well as semantics, usability, GenAI, trust and explainability enables answering questions like:
- Which platforms offer strong ontologies, inference, and semantic data fabric capabilities?
- Which property graph vendors actually package a knowledge graph solution instead of leaving it as a DIY project?
- Where can I get robust governance, provenance, and explainability for AI on top of my data?
- Which tools are best suited as KG‑centric search and discovery layers, or as GraphRAG backbones for GenAI applications?
- How far can I go toward production‑grade GenAI (with grounding, provenance, and mitigation) using the KG capabilities a given vendor offers today?
Inclusion Criteria: How We Drew the Boundaries
To keep the category focused, we set three concrete tests. An offering shows up in the Knowledge Graphs catalog only if it meets all of the following criteria:
- Knowledge Graph Model: Represents entities and relationships as a first‑class graph model (property graph, RDF, or other) for a specific domain.
- Knowledge Graph Creation: Provides a mechanism for ingesting, constructing, and updating the graph from multiple sources.
- Knowledge Graph Querying: Provides a query language for accessing and updating the graph across multi‑hop and knowledge‑centric use cases.
In addition, a knowledge graph offering must also meet at least 2 of the following 4 capability criteria:
- Semantic & Metadata Capabilities, such as metadata management, ontologies, inferencing, semantic data fabric, lineage, and harmonization.
- User Experience & Usability, including visualization, KG exploration, low‑code tools, collaboration, and curation workflows
- GenAI Support, such as GraphRAG, embeddings, vector search, and agentic AI integration, with those AI features tightly coupled to the KG.
- Trust & Explainability, including provenance, lineage, schema governance, audit trails, fact grounding, hallucination mitigation, compliance, and uncertainty.
We do not assume that knowledge graphs can only be built with RDF or triple stores. Both RDF stores and property graph platforms can support robust knowledge graphs. That is why you will see RDF‑centric vendors and property graph vendors side by side in this catalog: all of them meet the same inclusion criteria for modeling, building, and productizing knowledge graphs.
This is why, for example, property‑graph platforms like Neo4j, Memgraph, FalkorDB, and ArangoDB appear alongside RDF‑centric platforms like AllegroGraph, GraphDB, eccenca, Stardog, TopQuadrant, and TrustGraph: all are productizing knowledge graphs under these criteria, and many now position them explicitly as GenAI‑ready or GraphRAG‑ready foundations.
What This First Cut Reveals
Even in this first iteration, several patterns stand out across the knowledge graph landscape. These are the kinds of signals State of the Graph aims to surface for knowledge graphs: where the center of gravity is, how approaches cluster, and how quickly GenAI and GraphRAG are reshaping the category.
Two strong lineages rather than one dominant stack
We see a mature RDF/OWL ecosystem and a vibrant property‑graph and converged‑engine cohort, both of which frame their offerings as knowledge graphs. Property‑graph‑centric and converged platforms tend to emphasize flexible schemas, graph query languages like Cypher or Gremlin, and tight integration with existing application stacks, while RDF‑centric platforms lean into ontologies, SPARQL, inferencing, and standards‑driven interoperability.
Different levels of semantic depth
Some vendors offer full semantic data fabrics, including rich ontologies, inferencing, semantic lineage, and cross‑source harmonization. Others provide “semantic‑lite” or metadata‑driven KGs that still give you entities, relationships, and context, but without a heavy OWL/RDFS stack. This split matters if you are choosing between standards‑driven interoperability or more pragmatic, app‑centric KGs.
Trust, governance, and AI‑safety as differentiators
Provenance, lineage, schema governance, auditability, fact grounding, and hallucination mitigation are becoming major axes of differentiation, especially where KGs underpin AI systems that must be explainable and controllable. Some platforms offer a near‑complete “trust stack,” while others are still at the level of basic explainability or governance.
GenAI and GraphRAG moving to the center
A growing share of the category treats GraphRAG, KG‑grounded agents, embeddings, and vector‑augmented KGs as first‑class scenarios, with property‑graph and converged-engine approaches often leading in developer‑facing GraphRAG tooling, while RDF‑centric platforms lean into semantic grounding and regulatory use cases.
The story is shifting from “knowledge graphs for search and BI” toward “knowledge graphs as the control plane and grounding layer for GenAI,” with competing claims about retrieval quality, provenance, safety, and tool/agent orchestration.
How Knowledge Graphs Fit into State of the Graph
Knowledge Graphs are one part of the broader State of the Graph landscape, which also examines:
- Graph databases
- Graph engines
- Graph analytics
- Graph visualization
- Graph application development
- Graph AI
Across these categories, the common thread is a structured, comparative view of offerings, framed in terms that match how practitioners actually evaluate and use graph technology. The Knowledge Graphs catalog extends that lens into the space where modeling, semantics, governance, GenAI, and trust meet.
Help Us Improve the Knowledge Graphs Map
This is a first‑round map, and we expect it to evolve. Some boundaries between categories will remain blurry. There may be vendors we have not yet included, and capabilities we have under‑ or overstated.
Your experience is what will make this useful:
- Which platforms are you using today to build production knowledge graphs or GraphRAG pipelines?
- Who is missing under the current criteria?
- Where did we misjudge the strength of semantic, GenAI, or trust features?
- How should we refine the way we group and describe these offerings?
If you are designing, implementing, or operating knowledge graphs, or building tools in this space, we’d love your feedback on this first version.
Explore the Knowledge Graphs catalog and tell us what to add, adjust, or clarify. Your input will guide the next iteration of this category and the broader State of the Graph.

Leave a Reply